BCG InstituteBCGi
Criterion-Related Validity
Overview
The Uniform Guidelines define criterion-related validity as, “Data showing that a selection procedure is predictive of, or significantly correlated with, important elements of job performance.” How is this different than content validity? First let’s consider what criterion-related validity can do that content validity cannot.
The Uniform Guidelines state that a content validity strategy is “ . . . not appropriate for demonstrating the validity of selection procedures which purport to measure traits or constructs such as intelligence, aptitude, personality, common sense, judgment, leadership, and spatial ability” (Section 14C1). It has been mentioned previously that content validity can, in fact, be used to measure some of these “more abstract traits” if they are operationally defined in terms of observable aspects of the job (see Section 14C4 and Questions & Answers #75). That is, if they are converted from “generic abstracts” into concrete, measurable characteristics that are defined in ways they can be observed on the job, they are fair game for measurement under a content validation strategy.
But what if they cannot be converted in this way? Is it permissible to measure these traits at all? Yes, and this is where criterion-related validity comes in. Hypothetically speaking, an employer defending a selection procedure that is based on criterion-related validity could stand up in court and say:
Your honor, I don’t know exactly what this test is measuring, but I do know it works. Applicants who score high on this test typically turn out to be our best workers, and applicants who score low typically do not. We know this because we conducted a study where we correlated test scores to job performance ratings and the study showed a correlation of .35, which is statistically significant at the .01 level—meaning that we are highly assured that the relationship between test scores and job performance is well beyond what we would expect by chance alone.*
It would be nice if the defense of a selection procedure based on criterion-related validity was this simple! This “simple defense,” however, is in fact true in concept. Content validity battles in litigation are always much more involved, with experts fighting over the complex nuances of what constitutes a “defensible content validity study” that addresses government and professional standards. This is because criterion-related validity is by nature empirical—the employer either has a statistically significant correlation or does not. With content validation, the end decision regarding its merit is typically based on a judgment call regarding the relative degree of content validity evidence that exists based on a job analysis remaining parts of the study.
Criterion-related validity studies can be conducted in one of two ways: using a predictive model or a concurrent model. A predictive model is conducted when applicant test scores are correlated to subsequent measures of job performance (e.g., six months after the tested applicants are hired). A concurrent model is conducted by giving a selection procedure to incumbents who are currently on the job and then correlating these scores to current measures of job performance (e.g., performance review scores, supervisor ratings, etc.).
Before going into detail regarding the mechanics on how to complete a criterion-related validity study using either of these two methods, a brief caution is provided first. Completing a criterion-related validity study is a gamble. If an employer has been using a written test for years, and has never completed any type of study to evaluate its validity, a criterion-related validity study would be the easiest type of validation study to conduct. Just gather selection procedure scores for applicants who have been hired over the past several years and enter them into a column in a spreadsheet next to another column containing their average performance ratings, use the =PEARSON command Microsoft® Excel® to correlate the two columns and presto! Instant validity. Or not.
If the resulting correlation value from the Pearson command is statistically significant, good news: your selection procedure is valid (providing that a host of other issues are addressed!) But what if the correlation value is a big, round zero (meaning no validity whatsoever)? Even worse, what if the correlation is negative (indicating the best test takers are the worst job performers)?
If this type of “quick correlation study” is conducted, and the employer had a sufficient sample size (see discussion below on statistical power), they just invalidated their selection procedure! The drawback? The employer is now open for lawsuits if the information is exposed, or negative information is now available if a lawsuit is currently pending. The benefit? Now the employer can discontinue using the invalid selection procedure and replace it with something much better. This dilemma is referred to among personnel researchers as the “validator’s gamble.”
* This hypothetical example, of course, assumes that the employer adequately addressed all of the nuances required for defensible criterion-related validity studies.
Steps for Completing a Criterion-Related Validity Study
Before reviewing the steps to complete a criterion-related validity study, a brief discussion on statistical power and reliability are necessary. The reason for this is simple. Without these two ingredients, the rest of the recipe does not matter! Conducting a criterion-related validity study without sufficiently high statistical power and reliability is like trying to bake bread without yeast.
Statistical Power (as it Relates to Criterion-Validation)
Statistical power is the ability of a statistical test (in this case, a Pearson Correlation) to detect a statistically significant result if it exists to be found. In the case of correlations, statistical power highly depends on the size of the correlation coefficient the researcher expects to find in the population being sampled. If the researcher suspects that there is a (decent sized) correlation coefficient of .30 in the sample being researched (and they suspect that this correlation can only be in the favorable direction—positive—which requires a one-tail statistical test), 64 subjects are necessary to be 80% confident (i.e., to have 80% power) that the study will result in a statistically significant finding at the .05 level (if it is exists in the population). If the researcher suspects a smaller, but still significant correlation of .20 exists in the population, 150 subjects are necessary for the same levels of power.
To avoid a gamble, use at least 200. Using a large sample will provide the researcher with high levels of power to find a statistically significant finding if it exists and will provide assurance that if the study did not result in a statistically significant finding that it was not because the sample was too small (but rather because such a finding just did not exist in the first place!).
Criterion and Selection Procedure Reliability
It is noted in the steps below that both the criterion measures (e.g., supervisor ratings) and selection procedures (e.g., a written test in the study) should have sufficiently high levels of reliability (at least .60 for the criterion measures and .70 or higher for the selection procedures). The reason for this can be explained with a simple rational explanation, followed by some easy math.
The rational reason why an unreliable measure (i.e., the criterion measure or the selection procedure) can spoil a criterion-related validation study is this: if a measure is inconsistent (unreliable) by itself, it will also be inconsistent when asked to (mathematically) cooperate with another variable (as in the case of the correlation required for criterion-related validity). A selection procedure that is not sure about what it is measuring by itself will not be any more sure about what its measuring related to another variable (like the criterion measure)!
Mathematically, this is explained with a concept called the “theoretical maximum,” which states that the maximum correlation that two variables can produce is limited by the square root of the product of their reliability coefficients. How does this work out practically? Consider a selection procedure with a reliability of .80 and a criterion measure with a low reliability of .40. The maximum correlation one can expect given the unreliability of these two variables (especially the criterion measure) is .57. If the reliabilities are .50 and .60, the maximum correlation that can be obtained is .55. With reliabilities of .90 and .60, a maximum of .73 is possible. With this caution, be sure that the criterion measure and the selection procedure have sufficiently high levels of reliability! A researcher will be quite disappointed to go through the steps for completing a criterion-related validation process, only to find out that the study did not stand a chance in the first place of resulting with significant findings!
So, assuming that the researcher has a sufficiently large sample (power), and reliable criterion measures and selection procedures, the following steps can be completed to conduct a predictive criterion-related validity study:
- Conduct a job analysis (see previous section) or a “review of job information.” Unlike content validity, a complete A to Z job analysis is not necessary for a criterion-related validity study (see Sections 14B3 and 15B3 of the Uniform Guidelines).
- Develop one or more criterion measures by developing subjective (e.g., rating scales) or objective measures (e.g., absenteeism, work output levels) of critical areas from the job analysis or job information review. A subjectively rated criterion can only consist of performance on a job duty (or group of duties). It cannot consist of a supervisor or peer’s rating on the incumbent’s level of KSAPCs (a requirement based on Section 15B5 of the Uniform Guidelines). It is critical that these measures have sufficiently high reliability (at least .60 or higher is preferred).
- Work with Job Experts and supervisors, trainers, other management staff, and the Job Analysis data to form solid speculations (“hypotheses”) regarding which KSAPCs “really make a difference” in the high/low scores of such job performance measures (above). Important: if the Job Analysis for the position included Best Worker ratings, these should provide a good indicator regarding the KSAPCs that distinguish job performance in a meaningful way. These ratings can be used to key in on the prime KSAPCs that are most likely to result in a significant correlation with job performance measures.
- Develop selection procedures that are reliable measures of those KSAPCs. Choosing selection procedures that have reliability of .70 or higher is preferred.
- After a period of time has passed and criterion data has been gathered (e.g., 3 – 12 months), correlate each of the selection procedures to the criterion measures using the PEARSON command in Microsoft® Excel® and evaluate the results*.
To complete a concurrent criterion-related validation study, complete steps 1 – 4 above and replace Step 5 by administering the selection procedure to the current incumbent population and correlate the selection procedure scores to current measures of job performance.
Let’s now assume your study output one or more significant correlations. How can these be interpreted? The US Department of Labor (2000, p. 3-10) has provided the following reasonable guidelines for interpreting correlation coefficients:
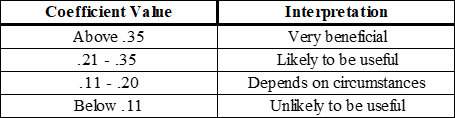
Table 2‑3 Guidelines for Interpreting Correlations
* The reader is cautioned against making too many correlational comparisons because doing so increases the odds of finding statistically significant correlations that are due to chance alone.
Advanced Criterion-Related Validity Topics
This text is designed to provide a fundamental overview of the key components of a criterion-related validity study. Because this type of validation is statistical in nature, there is a practically endless scope of tools, calculations, and issues related to this topic. Some are outlined below:
- Expectancy tables and charts. Once a statistically significant correlation has been identified, there are a vast number of calculations that can be used to practically evaluate the impact of using the validated selection procedure in a selection process. Expectancy tables can show, with mathematical accuracy, the expected increase in job performance that can be obtained by ratcheting up (or down) the cutoff used for the selection procedure. For example, a selection procedure with a high correlation to job performance might show that if the employer uses a cutoff of 65% on the selection procedure that expected job performance levels would be a “6.0” (on a scale of 1 – 9); whereas a cutoff of 80% might equate to a 7.0, etc. The reader is referred to a statistical program titled “Theoretical Expectancy Calculator” by Personnel Decisions International Corporation for a useful tool for making these (and other related) calculations.
- Cross validation. This is another important concept related to criterion-related validity studies. Cross validation is a useful tool for determining the transportability or “generalizability” of one study’s findings to another setting. This can be done mathematically using formulas that adjust the correlation coefficient found in one study, or empirically by taking the selection procedure to that other setting and evaluating the correlation coefficient found in the new setting. It should be noted that correlation values almost always get smaller when this process is done, which means that the correlation value obtained in a single sample are often inflated due to the unique characteristics of that employer, selection procedure, and the combination thereof.
- Corrections. Statistical correlations are typically repressed (i.e., smaller than they could be) because of a phenomena called range restriction (that occurs on the selection procedure and/or criterion measures) and because of the unreliability of the criterion and/or the selection procedure. Range restriction occurs on the selection procedure when some of the applicant scores are not included in the study (because they failed the selection procedure). Range restriction occurs on the criterion measure when some of the job incumbents self-select out of the sample (e.g., by finding another job) or are terminated. Range restriction reduces the amount of variance in the correlation study, which lowers the power of the study (an ideal study is one that includes both the low- and high-end of test takers and job performers). Corrections can also be made to adjust for the unreliability of the criterion measure, but corrections should not be made to the selection procedure (because this is a real limitation that is present in both the study and in the future use of the selection procedure). Formulas to correct for range restriction and unreliability can be found in Guion, 1998; Cascio, 1998; and Hubert & Feild, 1994.
- Bias. If an adequate sample exists for minorities and/or women (typically a minimum rule of 30 are necessary), a study of bias can be conducted to assess whether the selection procedure is a fair and accurate predictor for both majority and minority groups. The procedures for conducting such studies can also be found in Guion, 1998; Cascio, 1998; and Hubert & Feild, 1994.
The Elements of a Criterion-Related Validity Study that are Typically Evaluated in Title VII Situations
When the courts evaluate criterion-related validity evidence, which is the type of evidence of validity that can be included in statistical VG studies, four basic elements are typically brought under inspection: Statistical significance, practical significance, the type and relevance of the job criteria, and evidence available to support the specific use of the testing practice. If any of these elements are missing or do not meet certain standards, courts often infer that discrimination has taken place because adverse impact is not justified without validity evidence. Each of these elements is discussed in more detail below.
Statistical significance. The courts, Uniform Guidelines, and professional standards are in agreement when it comes to the issue of statistical significance thresholds and criterion-related validity. The .05 threshold is used on both sides of adverse impact litigation for determining statistically significant adverse impact (using hypergeometric probability distributions for testing cases) as well as determining the statistical significance of the correlation coefficient obtained in the validation study.
Practical significance. Just like statistical significance, the concept of practical significance has also been applied to both the adverse impact and validity side of Title VII cases. In the realm of adverse impact, the courts have sometimes evaluated the practical significance or “stability” and effect size of the adverse impact.* This is typically done by evaluating what happens to the statistical significance finding when two applicants are hypothetically changed from failing to passing status on the selection procedure that exhibited adverse impact. If this changes the statistically significant finding from “significant” (<.05) to “non-significant” (>.05), the finding is not practically significant.
In the realm of criterion-related validity studies, practical significance relates to the strength of the validity coefficient (i.e., its raw value and actual utility in the specific setting). This is important in litigation settings because the square of the validity coefficient represents the percentage of variance explained on the criterion used in the study. For example, a validity coefficient of .15 explains only 2.3% of the criterion variance, whereas coefficients of .25 and .35 explain 6.3% and 12.3% respectively. Some cases have included lengthy deliberations about these “squared coefficient” values to argue the extent to which the test validity is practically significant. A few examples are provided below.
- Dickerson v. U. S. Steel Corporation (1978): A validity study was inadequate where the correlation level was less than .30, the adverse impact on minorities from the use of the selection procedure was severe, and no evidence was presented regarding the evaluation of alternative selection procedures. Regarding the validity coefficients in the case, the judge noted, “a low coefficient, even though statistically significant, may indicate a low practical utility” and further stated, “. . . one can readily see that even on the statistically significant correlations of .30 or so, only 9% of the success on the job is attributable to success on the (test) batteries. This is a very low level, which does not justify use of these batteries, where correlations are all below .30. In conclusion, based upon the guidelines and statistical analysis . . . the Court cannot find that these tests have any real practical utility. The Guidelines do not permit a finding of job-relatedness where statistical but not practical significance is shown. On this final ground as well, therefore, the test batteries must be rejected” (emphasis added)
- NAACP Ensley Branch v. Seibels (1980): Judge Pointer rejected statistically significant correlations of .21, because they were too small to be meaningful.
- EEOC v. Atlas Paper (1989): The judge weighed the decision heavily based on the strength of the validity coefficient: “There are other problems with Hunter’s theory which further highlight the invalidity of the Atlas argument. Petty computed the average correlation for the studies to be .25 when concurrent and .15 when predictive. A correlation of .25 means that a test explains only 5% to 6% of job performance. Yet, Courts generally accept correlation coefficients above .30 as reliable . . . This Court need not rule at this juncture on the figure that it will adopt as the bare minimum correlation. Nonetheless, the Court also notes that higher correlations are often sought when there is great adverse impact (Clady v. County of Los Angeles, id; Guardians Assn of New York City v. Civil Service, 630 F.2d at 105-06). Thus, despite the great adverse impact here, the correlations fall significantly below those generally accepted (FN24).”
- U.S. v. City of Garland (2004): The court debated the level of the validity coefficients extensively: “As discussed supra at n. 25, whether the correlation between the Alert (test) and performance should be characterized as “low” or “moderate” is a matter of earnest contention between the parties. (See D.I. 302 at p. 11, 35-40.) In a standard statistical text cited at trial, correlations of .1 are described as “low” and correlations of .30 described as “moderate.”
In addition to the courts, the Uniform Guidelines (15B6), U.S. Department of Labor (2000, p. 3-10), and SIOP Principles (p. 48) are in concert regarding the importance of taking the strength of the validity coefficient into practical consideration.
Type and relevance of the job criteria. There are many cases that have deliberated the type and relevance of the job criteria included as part of a validity study, including Garland, Lanning, and others cited herein. The Uniform Guidelines (15B5) and SIOP Principles (p. 16) also include discussion on this topic. Tests that have significant correlations with job criteria that are reliable and constitute critical aspects of the job will obviously be given higher weight when evaluated.
Considering the validity coefficient level and the specific use of the testing practice. Some cases have set minimum thresholds for validity coefficients that are necessary to justify the particular use of a test (e.g., ranking versus using a pass/fail cutoff). Conceptually speaking, tests that have high levels of reliability (i.e., accuracy in defining true ability levels of applicants) and have high validity can be used at a higher degree of specificity than tests that do not have such characteristics (e.g., Guardians Association of the New York City Police Dept. v. Civil Service Commission, 1981). When tests are used as ranking devices, they are typically subjected to a stricter validity standard than when pass/fail cutoffs are used. The cases below placed minimum thresholds on the validity coefficient necessary for strict rank ordering on a test:
- Brunet v. City of Columbus (1993): This case involved an entry-level firefighter Physical Capacities Test (PCT) that had adverse impact against women. The court stated, “The correlation coefficient for the overall PCT is .29. Other courts have found such correlation coefficients to be predictive of job performance, thus indicating the appropriateness of ranking where the correlation coefficient value is .30 or better.”
- Boston Chapter, NAACP Inc. v. Beecher (1974): This case involved an entry-level written test for firefighters. Regarding the correlation values, the court stated: “The objective portion of the study produced several correlations that were statistically significant (likely to occur by chance in fewer than five of one hundred similar cases) and practically significant (correlation of .30 or higher, thus explaining more than 9% or more of the observed variation).”
- Clady v. County of Los Angeles (1985): This case involved an entry-level written test for firefighters. The court stated: “In conclusion, the County’s validation studies demonstrate legally sufficient correlation to success at the Academy and performance on the job. Courts generally accept correlation coefficients above .30 as reliable … As a general principle, the greater the test’s adverse impact, the higher the correlation which will be required.”
- Zamlen v. City of Cleveland (1988): This case involved several different entry-level firefighter physical ability tests that had various correlation coefficients with job performance. The judge noted that, “Correlation coefficients of .30 or greater are considered high by industrial psychologists” and set a criteria of .30 to endorse the City’s option of using the physical ability test as a ranking device.
The Uniform Guidelines (3B, 5G, and 15B6) and SIOP Principles (p. 49) also advise taking the level of validity into consideration when considering how to use a test in a selection process. Test usage is such a critical consideration because validity has to do with the interpretation of individual scores. Tests, per se, are not necessarily generally valid; rather, specific scores may or may not be valid given consideration of how closely they are aligned with the true needs of the job. A keyboarding speed and accuracy test may be valid for both the positions of a personnel psychologist and a legal secretary; but the cutoff of 85 words per minute is certainly more valid for the legal secretary position than it is for the personnel psychologist position.
In the event of a Title VII case, practitioners who rely solely on a VG study to infer validity evidence into a new situation will not have information on these four critical factors to provide the court. Because VG relies essentially on inferring validity based on other studies, there is no way to tell if a local study would result in a validity coefficient that is statistically significant, if such validity coefficient would be practically significant, if the job criteria predicted was relevant given the needs of the particular position, or if the validity coefficient would sufficiently justify the specific use of the testing practice. This presents a challenge when opting to deploy a VG-only defense in Title VII situations. Each of these is discussed in more detail below.
By relying solely on a VG study, there is no way to determine whether a validity coefficient would be statistically significant in a local situation because no local validity coefficients were ever calculated. While VG studies can generate estimated population validity coefficients (with various types of corrections), it is not possible to determine if such validity coefficient would be obtained in the local situation, and (more importantly), whether it would exceed the court-required level needed for statistical significance (<.05). Even if one considers the population validity coefficient calculated from a VG study at face value (e.g., r = .25), calculating the statistical significance level requires also knowing the sample size included in the study, which is another unknown unless a local study is in fact conducted. For example, a coefficient of .20 is significant with a sample of 69 (p = .0496 using a one-tail test for significance), but is not significant with a sample of 68 (p = .051). The first can be argued as defensible under Title VII; the other is not.
Without knowing what the actual validity coefficient would be in a local situation, it is also not possible to evaluate its practical significance in the local job context. While contemporary VG techniques include the 90% credibility interval to forecast the minimum size the validity coefficient is likely to be in similar situations outside the VG study, one must still guess what the actual validity actually would have been in the specific situation. In some circumstances, judges may be more inclined to make determinations whether the test would “survive scrutiny” in light of the situational factors of the case only after he/she has the actual validity number (see several such cases above).
The exact level of adverse impact is always known in Title VII situations. This is because the impact is what brought the suit/audit in the first place and is typically reported in standard deviation units reflecting the statistical probability level of the finding. How will judges handle situations where the adverse impact level is known, but the level of correlation (validity) in that same situation is not? Some cases include lengthy discussions regarding the strength of the validity evidence (e.g., Dickerson, Garland, and Zamlen). Oftentimes VG studies include a wide mix of various job criteria predicted by a test and, without conducting a local study, there is no way to tell if the test would in fact be correlated to the job criteria of the position in the local setting that would be sufficiently important to the overall job. The Uniform Guidelines offer a caution on this issue: “Sole reliance upon a single selection instrument which is related to only one of many job duties or aspects of job performance will also be subject to close review” (Section 14B6).
Finally, regarding the “specific use” criteria, the cases discussed above provide several examples of litigation settings where defendants have been required to weigh their validity evidence to support the specific use of the test under scrutiny (with ranking being the most highly scrutinized). The Uniform Guidelines advise that tests should be evaluated to insure its appropriateness for operational use, including setting cutoff scores or rank ordering (Section 15B6). Only local validity studies reveal the actual validity level of a test in a certain situation. While provisions exist in the Uniform Guidelines for justifying test use in various circumstances, local validity studies offer the added benefit of producing the known validity level of a test.
* For example, Contreras v. City of Los Angeles (656 F.2d 1267, 9th Cir., 1981), U.S. v. Commonwealth of Virginia (569 F2d 1300, CA-4 1978, 454 F. Supp. 1077), Waisome v. Port Authority (948 F.2d 1370, 1376, 2d Cir., 1991).